In the mid to late 1990s as the Web developed, it was becoming more obvious that one area it would revolutionise was of scholarly journal publishing. Since the days of the very first scientific journals in the 1650s, the medium had been firmly rooted in paper. Even printed colour only became common (and affordable) from the 1980s. An opportunity to move away from these restrictions was provided by the Web. Early adopters of this medium in chemistry were the CLIC pilot project[1] in 1995 and the Internet Journal of Chemistry (IJC), the latter offering “enhanced chemical publication which permits the publication of materials which cannot be published on paper and end-use customization which permits the readers to read articles prepared for their specific needs“.[2] Publication of the latter started in January 1998, offering “authors the opportunity to enhance their articles by fully incorporating multimedia, large data sets, Java applets, color images and interactive tools.” The journal remained online for seven years, after which it was closed and the articles became inaccessible. By then many major chemistry journals had started evolving along some of the same lines, and it could be argued this journal had served its purpose of alerting both publishers and authors to these new opportunities. Here I describe how an IJC article published in 2001 was brought back to life in more or less the enhanced manner intended.[3]
Entitled “The Mechanism and Design of Asymmetric Co-Arctate Br+ (Mobius) Atom Transfers Between Alkenes. A Computational Study“, an abstract of the article is still visible via services such as e.g. Scifinder, but a more complete and open metadata description which can be provided from an assigned DOI (Digital object identifier) is not available, since back in 2001 the adoption of DOIs by journals was still in its infancy. Fortunately, the original source was still available from the authors as a combination of HTML, image files and data, the latter two being hyperlinked into the body of the article. These files are in fact all that is needed to recreate the original IJC article (if not its style), using the mechanism of a data repository[4],[5] rather than that normally designed for a journal. The procedure adopted was as follows:
- All the data files were uploaded to the repository as a dataset.[6], DOI: 10.14469/hpc/13929.
- The metadata record generated and registered for these depositions (https://data.datacite.org/application/vnd.datacite.datacite+xml/10.14469/hpc/13929) has Access (the A of FAIR) identifiers in the form of e.g.
- <relatedIdentifier relatedIdentifierType="URL" relationType="HasPart">https://data.hpc.imperial.ac.uk/resolve/?doi=13929&file=1</relatedIdentifier>
- Descriptive metadata providing further properties if needed, such as file names and media types and file sizes can be obtained via
- <relatedIdentifier relatedIdentifierType="URL" relationType="HasMetadata">https://data.hpc.imperial.ac.uk/resolve/?ore=13929</relatedIdentifier>
- These access identifiers replaced the hyperlinks in the original article HTML
- Originally: <a href="supplemental/3-ts-rh3.pdb">-1.5</a>
- Becomes: <a href="https://data.hpc.imperial.ac.uk/resolve/?doi=13929&file=54">-1.5</a>
- It is worth noting that there are basically two methods of accessing a file. The first relies on its relative path in a hierarchical file system. Hard-coding such a location into a URL means it may not be persistent – the hyperlink is vulnerable to “link rot” when the file system is reorganised and the path to the file changes. The second method relies on a database query, which should be rather more persistent, since the database should always incorporate any reorganisation of the internal systems. A third option (not used here) is to assign a persistent identifier to every file, and to ensure that a properly persistent direct access mechanism is described in metadata for that file.
- The root document for the article, given the reserved filename index.html was edited to reflect the changes in the hyperlinks.
- The article document index.html was now itself uploaded to the repository. In a conventional data repository, such a file invokes no specific actions, but in the repository used for this purpose it does have the reserved meaning of invoking in effect a preview or “LiveView” using the syntax
- <iframe name="liveview" src="https://data.hpc.imperial.ac.uk/resolve/?doi=13929&file=90"
width="100%" height="600" id="liveview"></iframe>
- <iframe name="liveview" src="https://data.hpc.imperial.ac.uk/resolve/?doi=13929&file=90"
- The article now functions much in the same way it would have done on IJC, albeit in one interesting way. The regular style adopted in journals is to place the ESI or electronic supporting information files into a separate enclave, linked via the article landing page by parochial mechanisms. In this instance the article and its data files are visible on the same page – it is a data repository after all – thus elevating the data to the same status as the article. Such elevation is often referred to as making “Data a first class citizen of the publication processes“.
- The opportunity now arose to incorporate an interactive tool based on the use of the JSmol molecule viewer.
- By adding an additional header to the HTML document containing a Javascript invocation of JSmol, selected data could be brought to life by creating a molecular model in a separate window.
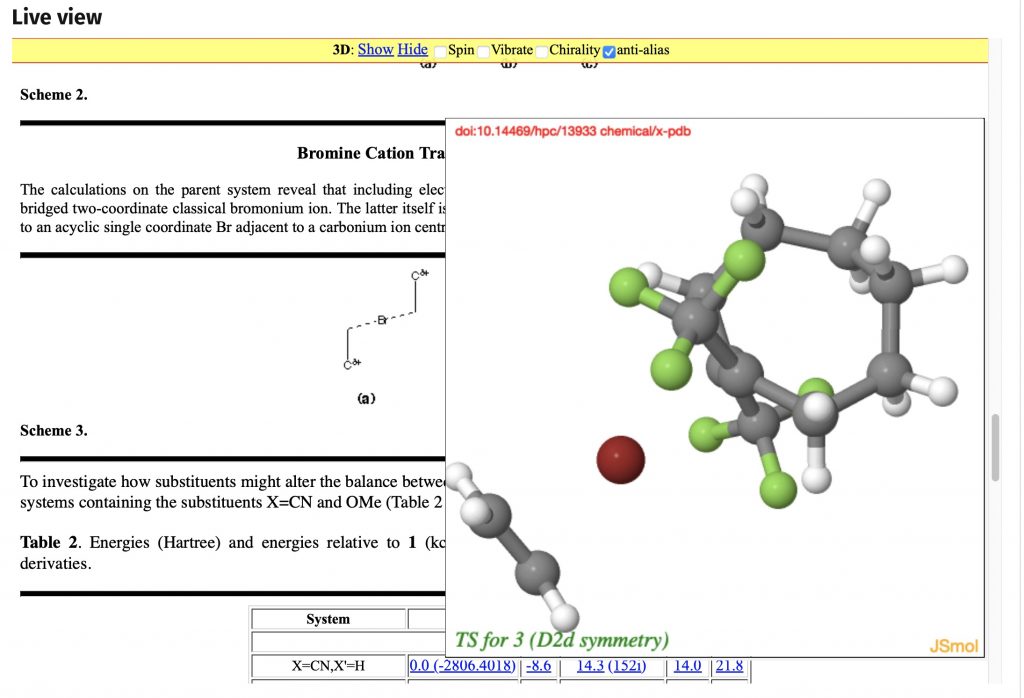
- This is invoked by a variation on the hyperlink shown above in section 3.2 by
<a href="javascript:show_jmol();javascript:handle_jmol('10.14469/hpc/13933',%20';frame 1;font label 16;zoom 5;moveto 4 90 4 80 65 120;spin 3;set echo bottom left;font echo 20 serif bolditalic;color echo green;echo TS for 3 (C2 symmetry);')">Load 3D Model</a> - Additional tools are now provided, from activating a (molecular) vibration, calculating a chirality (if applicable) or others invoked from a pull-down menu.
- In this example, the data is again accessed directly from a data repository, albeit by a different mechanism from that shown in 3.2 and here based only on the DOI of the data and its media type (in this case chemical/x-mdl-molfile).
- By adding an additional header to the HTML document containing a Javascript invocation of JSmol, selected data could be brought to life by creating a molecular model in a separate window.
It was not the intention here to illustrate how a Journal infrastructure might work – merely to rescue an article published 23 years ago (a long time in the Internet era) from a journal that is no longer disseminating articles. In the process the article has acquired its own DOI (albeit as data and not journal article), something not available from the original journal and some level of interactivity of the type originally envisaged. The (manual) process took something around 2-3 hours to achieve, and would certainly need automating if it were to be used more than once. I take encouragement however that after so many years, it was still possible with relatively little effort to achieve this curation.
Author
References
- D. James, B.J. Whitaker, C. Hildyard, H.S. Rzepa, O. Casher, J.M. Goodman, D. Riddick, and P. Murray‐Rust, "The case for content integrity in electronic chemistry journals: The CLIC project", New Review of Information Networking, vol. 1, pp. 61-69, 1995. https://doi.org/10.1080/13614579509516846
- S.M. Bachrach, "The 21st century chemistry journal", Química Nova, vol. 22, pp. 273-276, 1999. https://doi.org/10.1590/s0100-40421999000200020
- H. Rzepa, "Internet Archeology: an example of a revitalised molecular resource with a new activity now built in.", 2020. https://doi.org/10.59350/9c769-34y25
- Re3data.Org., "Imperial College Research Computing Service Data Repository", 2016. https://doi.org/10.17616/r3k64n
- FAIRsharing Team., and , ., "FAIRsharing record for: Imperial College Research Computing Service Data Repository", 2018. https://doi.org/10.25504/fairsharing.letkjt
- H. Rzepa, "The Mechanism and Design of Asymmetric Co-Arctate Br+ (Mobius) Atom Transfers Between Alkenes. A Computational Study", 2024. https://doi.org/10.14469/hpc/13929