Back in early 2012, I pondered about the relationships between a science-based blog post and a science-based journal article[1]. This was in part induced by my discovering a blog plugin called Kcite, which allow a journal articles to be appended to the blog in the form of a numbered reference list. The only required input for Kcite was the DOI of the article (as you can see earlier in this paragraph). For around 500 posts after that moment, I always strove to add such references to my posts. Around 2016, I started including references to data in the form of repository DOIs to sit alongside the journal references, but this feature stopped working a year or two later because of changes in the metadata resolved by the DOI. Kcite itself lasted until January 2024 for this blog, when a required update to the software running the blog (WordPress) meant that it no longer worked and had to be removed as a plugin. Two years ago, Rogue Scholar (Science blogging on steroids) started coming along to the rescue.[2] ,[3] It provides some amazing automated features and infrastructure to blogs; I will illustrate from those listed on the top page of Rogue Scholar itself:
- No waiting time — blogs can join via a simple form. Blog posts are automatically archived within minutes after publication on your blog.
- No fees — blog posts are archived without fees to either readers or authors. Rogue Scholar is sustained by donations and sponsorships.
- Archived — blog posts are archived by Rogue Scholar, and semiannually by the Internet Archive Archive-It service.
- Findable — every blog post is searchable via rich metadata and full-text search.
- Citeable — every blog post is assigned a Digital Object Identifier (DOI), to make them citable and trackable. Rogue Scholar shows citations to blog posts found by Crossref.
- Interoperable — metadata are distributed via Crossref and ORCID, and downstream services using their metadata catalogs.
- Reusable — the full-text of every blog post is distributed under the terms of the Creative Commons Attribution 4.0 license.
- Communities — blog posts automatically become part of communities for your blog, the blog subject area, and topic communities based on blog post tags.
Part of the stuff that goes on behind the scenes is integration with CrossRef (which handles information about journal articles) and that in turn enables insights such as how Blogs abstracted by Rogue Scholar can be cited within journal articles and other blogs and gives some idea of the impact that these blogs are making. Here I illustrate some searches so enabled by having Rogue Scholar abstract a blog;
- https://rogue-scholar.org/search?q=references:*&sort=newest This shows that Rogue Scholar has captured (currently) 2003 references abstracted from blogs.
- https://rogue-scholar.org/communities/rzepa/records?q=references:*&sort=newest Of these (currently) 504 have come from mostly identifying the [4] entries in my own blogs.
- https://rogue-scholar.org/search?q=citations:*&sort=newest shows all citations of the blogs in the Rogue Scholar community, currently at 519.
- https://rogue-scholar.org/search?q=citations:10.59350/*&sort=newest This lists the number of citations originating from the DOI prefix 10.59350 (which is that of the Rogue Scholar community).
- https://docs.rogue-scholar.org/dashboard lists other statistics. This are revealing, indicating currently only 6% of posts currently have references, although the uptake of institutional origins (ROR) and researcher ID (ORCID) is much better.
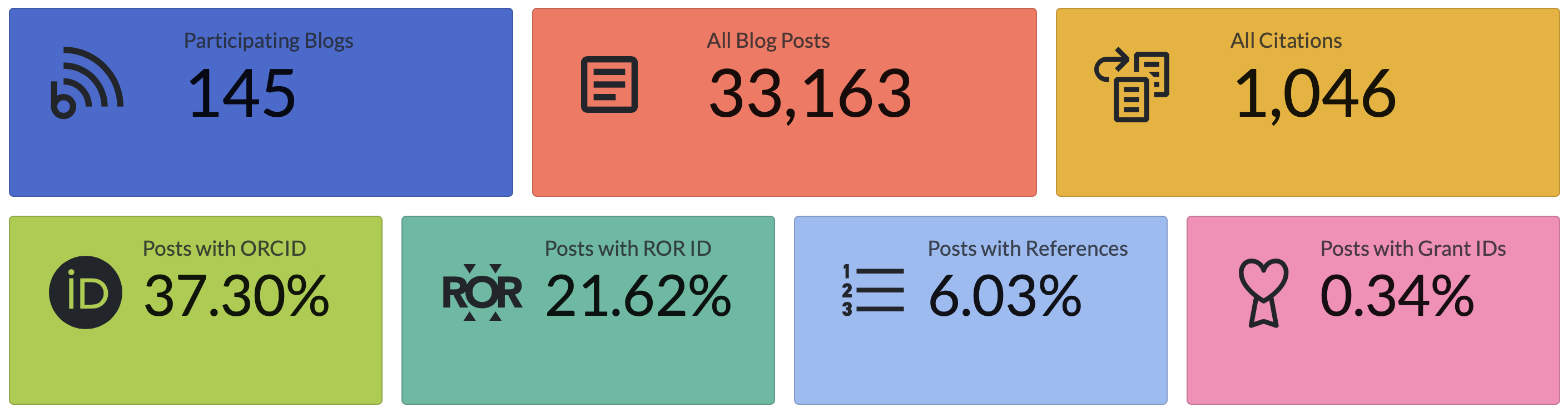
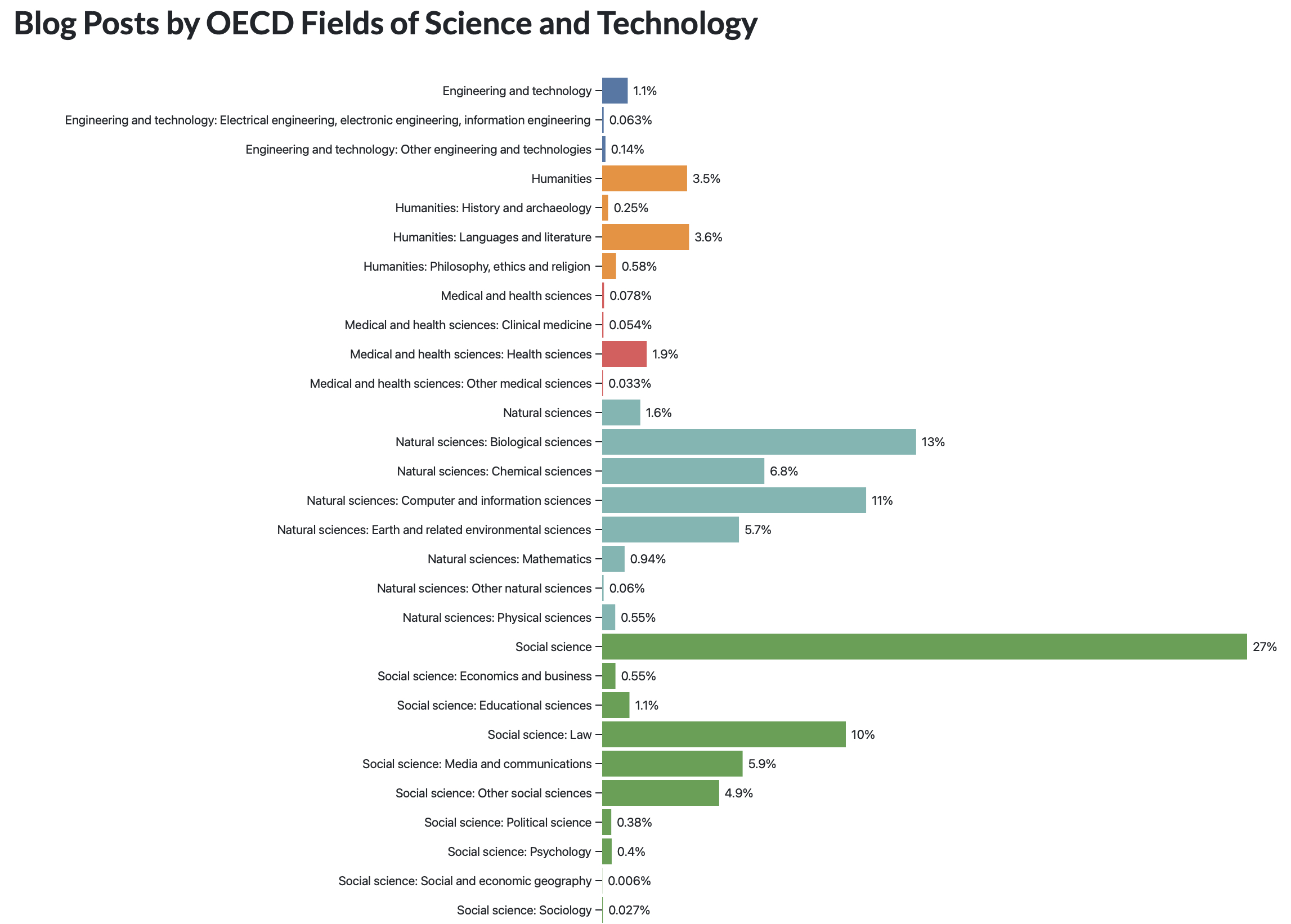
- The distribution amongst subject areas is 6.8% in the chemical sciences:
Meanwhile, work is under way to resuscitate the Kcite plugin, so that references are once again collected at the bottom of each post. Meanwhile, such a list can instead be found at the archived version of the posts at Rogue Scholar, as for example for this post itself. Also for the future is identifying how many of the references cited in blogs relate to research objects such as journal articles, and how many are instead to data held in e.g. data repositories. Such data reference richness in journal articles themselves is gradually increasing[5],[6] and it to be hoped also in science-based blogs themselves in the future.
Author
References
- H. Rzepa, "The blog post as a scientific article: citation management", 2012. https://doi.org/10.59350/3pbz1-vcd67
- M. Fenner, "Automatically list all your publications in your blog", 2013. https://doi.org/10.53731/axtz227-73n18e7
- M. Fenner, "Rogue Scholar now shows citations of science blog posts", 2025. https://doi.org/10.53731/4bvt3-hmd07
- https://doi.org/
- H. Rzepa, "Finding and Discovery Aids as part of data availability statements for research articles.", 2025. https://doi.org/10.59350/th26w-gev67
- D.C. Braddock, S. Lee, and H.S. Rzepa, "Modelling kinetic isotope effects for Swern oxidation using DFT-based transition state theory", Digital Discovery, vol. 3, pp. 1496-1508, 2024. https://doi.org/10.1039/d3dd00246b